Deploying robots such as autonomous cars in urban scenarios requires a holistic understanding of the environment with a unified perception of semantics, instances, and depth. While deep learning-based state-of-the-art approaches perform well when inference is done under similar conditions as used for training, their performance can drastically decrease when the new target domain differs from the source domain. This domain gap poses a great challenge for robotic platforms that are deployed in the open world without prior knowledge about the target domain. Additionally, unlike the source domain where ground truth annotations are generally assumed to be known and can be used for the initial training, such supervision is not applicable to the target domain due to the absence of labels, rendering classical domain adaptation methods unsuitable. Unsupervised domain adaptation attempts to overcome these limitations. However, the vast majority of proposed approaches focuses on sim-to-real domain adaptation mostly in an offline manner, i.e., a directed knowledge transfer without the need to avoid catastrophic forgetting and with access to abundant target annotations. Additionally, such works often do not consider limitations on a robotic platform, e.g., limited storage capacity.
CoDEPS
Continual Learning for Depth Estimation and Panoptic Segmentation
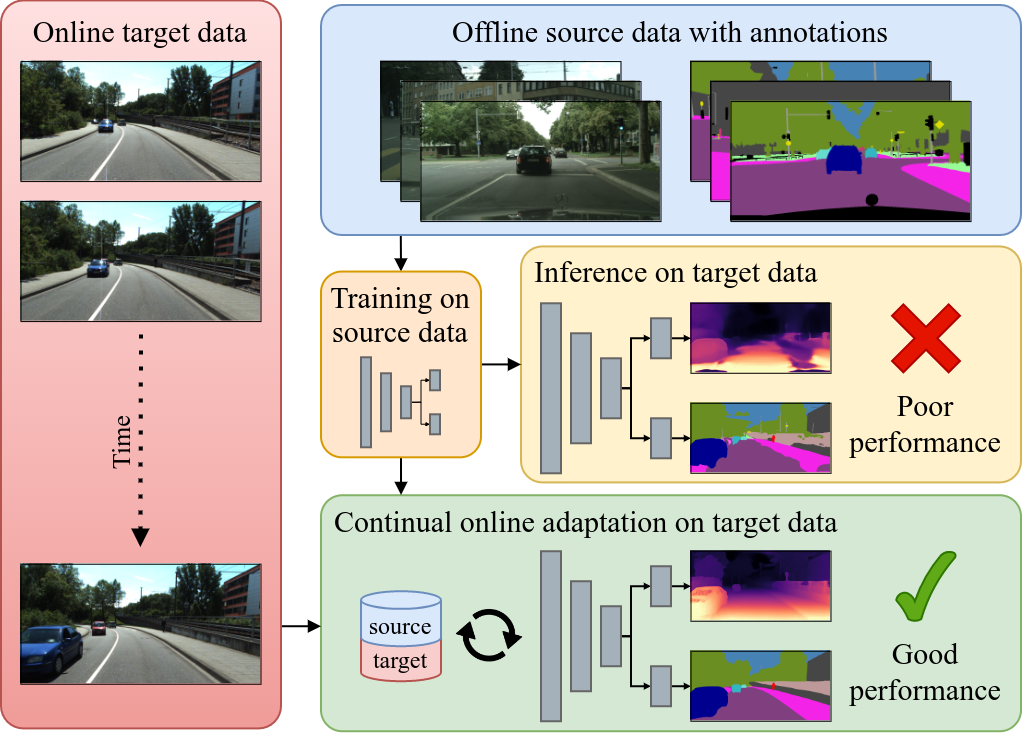
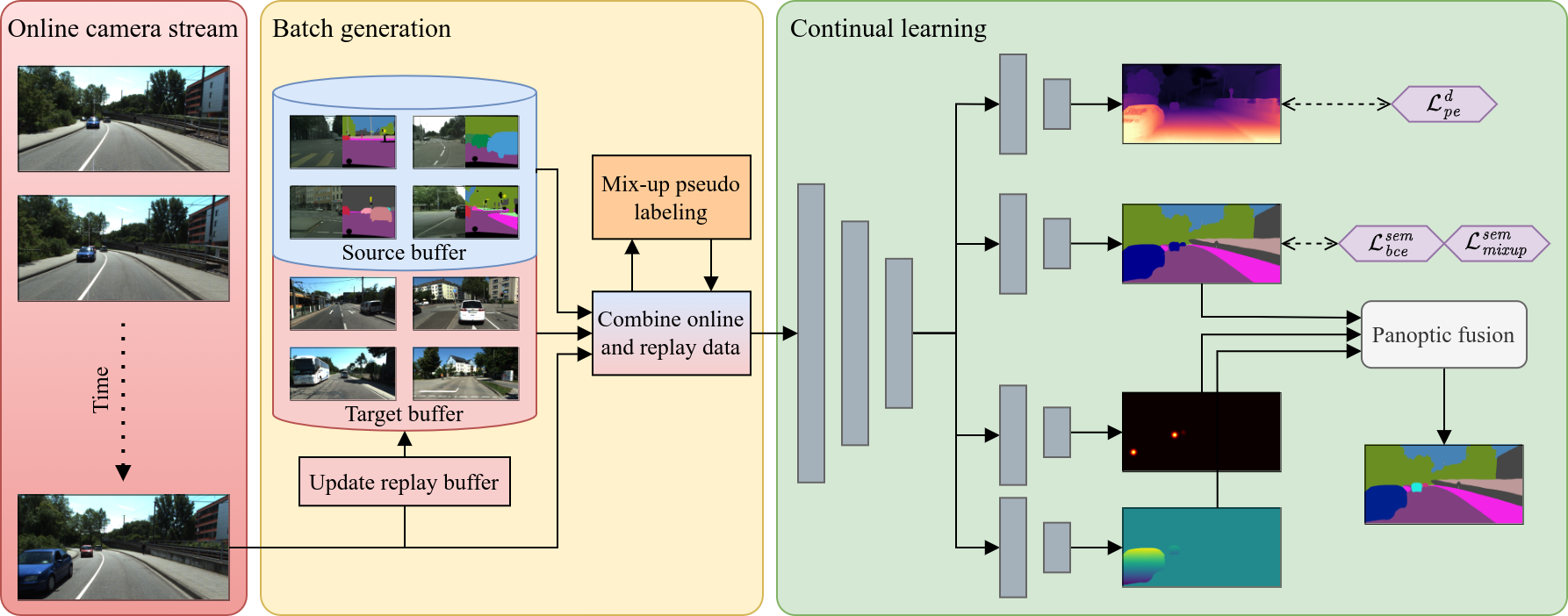
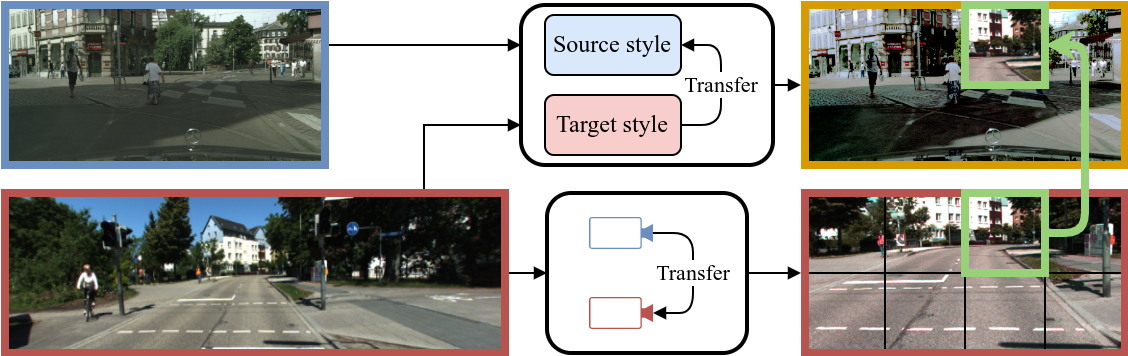
In this work, we use online continual learning to address these challenges for depth estimation and panoptic segmentation in a multi-task setup. In particular, we leverage images from an onboard camera to perform online continual learning enhancing performance during inference time. While a naive approach would result in overfitting to the current scene, our method CoDEPS mitigates forgetting by leveraging experience replay of both source data and previously seen target images. We combine a classical replay buffer with generative replay in the form of a novel cross-domain mixing strategy allowing us to exploit supervised ideas also for unlabeled target data. Unlike existing works, we explicitly address the aforementioned hardware limitations by using only a single GPU and restricting the replay buffer to a fixed size. We demonstrate that CoDEPS successfully improves on new target domains without sacrificing performance on previous domains.